Rabbitmq | 02 - Work Queues

Contents
实现一个用来在多个 Workers 之间分发
耗时任务的工作队列。那么为什么会出现工作队列呢?可以和上节的 Simple 队列做简单对比:
- Simple 队列是一一对应的,而且我们在实际开发过程中,生产者发送消息是毫不费力的, 而消费者则往往要和业务相结合,在接收到消息后要处理,就需要耗费时间,从而就导致了队列消息积压。
工作队列

工作队列设计的主要思想是为了避免这种情况的出现,即:有一堆资源密集型任务需要立即被执行,而且必须等待每个任务执行完成。与之相反的是,我们可以调度任务让它稍后再做。我们可以将任务封装成消息,发送给消息队列。运行在后台的工作进程就会从队列中取出任务并执行,如果有多个工作进程,则他们之间就会共享任务。
工作队列的设计在 Web 应用程序中就很有用,即:在一个短的 HTTP 请求窗口期不可能处理太复杂的耗时任务…
准备
- 耗时任务通过
time.Sleep()模拟 - 耗时时间通过
.的数量来表示,即:hello...将耗时三秒执行完成
调度任务:
new_task.go: 调度任务到工作队列中,任务通过命令行参数获取。改写 01-hello-world 的 send.go 代码,主要变化如下:
|
|
执行任务:
worker.go: 从工作队列中取出任务,根据消息体中的
.的数量,模拟任务执行耗时。改写 01-hello-world 的 recv.go 代码,主要变化如下:
|
|
运行程序:
Schedule Tasks
1 2# Open terminal A $ go run new_task.goExecute Task
1 2
# Open terminal B $ go run worker.go
轮询调度
使用消息队列的好处就是,可以很容易的实现并行工作
- 打开两个执行 worker.go
1 2 3 4 5# Open terminal A $ go run worker.go # Open terminal G $ go run worker.go打开四个终端执行四个耗时任务
|
|
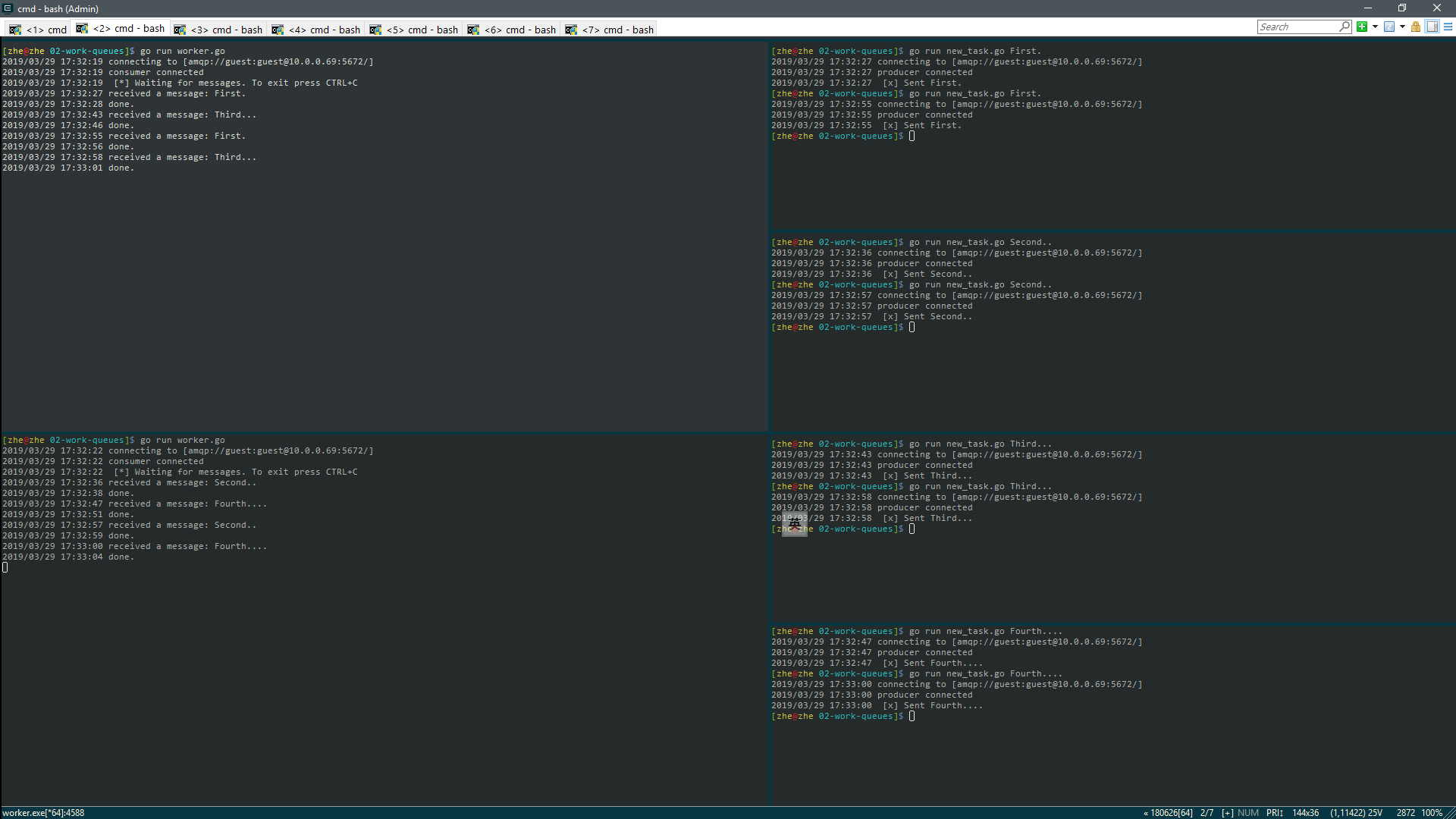
Note: 默认情况下,RabbitMQ 将会按顺序把消息发送给下一个消费者 ——
Round-Robin
消息应答
执行一个任务可能会花费数秒钟,如果一个任务执行需要很长的时间,而恰好执行一半时挂掉了会怎么样? 就拿我们当前的代码来说,一旦 RabbitMQ 把消息发送给消费者,就会立即标记删除,而且不会去关心消费者是否执行完毕。在这中情况下,如果你 Kill 掉一个正在执行的工作进程,那么就会丢掉这个消息了。同时,我们还会掉丢已经发送给这个消费者,但没有来得及处理的消息…
在很多情况下,我们并不希望丢失掉任何一条消息,比如:订单信息,支付信息等,而且在某个 worker 崩溃后,我们仍然希望可以将任务调度给其他的 worker 执行的话,该怎么做呢?
为了确保消息不丢失,RabbitMQ 支持了 消息确认:消费者完成消息接收,处理后,就发送一个
ack给 RabbitMQ,这时,RabbitMQ 就可以从内存中自由的删除这个消息了。
如果消费者没有返回给 RabbitMQ ack 消息就已经崩溃的话(崩溃的情况有:its channel is closed, connection is closed, or TCP connection is lost),RabbitMQ 就会认为这个消息没有被处理完成,然后将其重新排队。同时,如果有其他在线的 Consumer,RabbitMQ 会快速的将其分配给另一个消费者执行。这样,即使有 Worker 偶尔崩溃的情况下也依旧能保证消息不丢失。
消息确认没有超时机制,RabbitMQ 只会在消费者宕机后才会进行重新分发,因此,即使对于某些耗时很长的任务也不会有影响。
消息应答的两种方式:自动应答和手动应答
采用哪种消息应答模式则是在注册消费者时由 autoAck 参数来决定:
|
|
自动应答模式(默认):
|
|
手动应答:
|
|
So, 接下来修改代码:
worker.go 代码修改部分如下:将 Consume() 函数的 auto-ack 参数设为 false, 然后当任务处理完毕之后通过 d.Ack(false) 手动发送一个确认消息.
|
|
Note: 消息确认包必须发往消息传送进来时的通道,如果将确认包发送给其他通道时就会引起异常。
Forgotten acknowledgment
一个常见的错误就是忘记了对
消息进行确认 (ack), 这个错误看起来简单,但是会造成很严重的后果。当消费者程序退出后,消息就会被重新发送,而 RabbitMQ 因为无法释放掉未被确认的消息,就会导致消耗越来越多的内存而崩溃掉。可以使用
rabbitmqctl打印messages_unacknowledged字段的信息来调试这个错误:
$ sudo rabbitmqctl list_queues name messages_ready messages_unacknowledged
$ rabbitmqctl.bat list_queues name messages_ready messages_unacknowledged
消息持久化
前面我们了解到了,怎样在消费者服务宕机后保证消息不丢失;但,如果是 RabbitMQ 服务宕机仍然会使得消息丢失,这应该怎么处理呢?
当 RabbitMQ 退出或崩溃后,除非你明确的指定进行持久化,否则其所存储的队列和消息依旧会丢失。确保消息不丢失则要满足如下两个条件:将 队列 和 消息 标记为持久化。
首先:要保证 RabbitMQ 队列不丢失,则需将队列声明为持久化。
1 2 3 4 5q, err := ch.QueueDeclare( "hello", // name true, // durable:持久化 ... )Note: 这段代码看上去没有问题,但是在我们当前的配置中并不会起作用;因为我们在前面已经声明过名称为
hello,配置为未持久化的队列了;RabbitMQ 不允许声明多个名称相同而参数配置不同的队列,如果尝试这样做就会报错了。 一个快速有效的解决方案就是:重新声明新队列,代码如下:1 2 3 4 5q, err := ch.QueueDeclare( "task_queue", // name true, // durable:持久化 ... )Note:
durable参数在生产者和消费者程序中都要指定为true。接下来,需要标记消息为持久化:即配置
amqp.Publishing的DeliveryMode为amqp.Persistent,代码如下:1 2 3 4 5 6 7err = ch.Publish( ... amqp.Publishing { DeliveryMode: amqp.Persistent, // 消息持久化 ContentType: "text/plain", Body: []byte(body), })关于消息持久化需要注意:
- 将消息标记为持久化并不能完全保证消息不丢失;尽管 RabbitMQ 知道要将消息写入磁盘,但在 RabbitMQ 从接收消息到写入磁盘仍然会有一段很短的窗口期,这段时间就有可能造成消息丢失。因为 RabbitMQ 没有对每一个消息都执行
fsync(2), 因此消息可能只是写入了缓存而不是磁盘。 - 所以 Persistent 选项并不是完全强一致性的,但应付我们的简单场景已经足够。如需对消息完全持久化,可参考 publisher confirms.
公平分发
有时候,RabbitMQ 并不是按我们的期望进行任务调度,假设有如下场景:有两个消费者程序,所有
单数序列消息都是长耗时任务,而所有双数序列消息则都是简单任务,那么结果将会是一个消费者一直处于繁忙状态,另一个消费者几乎没有什么任务可做。然而,RabbitMQ 对此情况却是视而不见,仍然根据轮询来分发消息。导致上面情况发生的根本原因就是:RabbitMQ 是根据消息的入队顺序进行任务派发的。它并不关心某个消费者程序还有多少未被确认的消息,它只是简单的将第N条消息分发到第N个消费者:

为了避免这种情况,我们可以给队列设置
预取数(prefect count) 为 1。这将使得 RabbitMQ 不会一次性分发超过 1 个消息给某个消费者,换句话说就是:当分发给该消费者的前一个还没有收到ack确认时,RabbitMQ 将不会在给它派发消息,而是寻找下一个空闲的消费者进行分发。代码设置如下:1 2 3 4 5 6err = ch.Qos( 1, // prefetch count 0, // prefetch size false, // global ) failOnError(err, "Failed to set QoS")- 将消息标记为持久化并不能完全保证消息不丢失;尽管 RabbitMQ 知道要将消息写入磁盘,但在 RabbitMQ 从接收消息到写入磁盘仍然会有一段很短的窗口期,这段时间就有可能造成消息丢失。因为 RabbitMQ 没有对每一个消息都执行
关于队列长度:如果所有的消费者程序都繁忙的话,队列则可能会被消息塞满了。你需要注意这种情况,要么通过增加消费者来处理,要么改用其他的策略。
完整代码:Golang Intro: 02 | Work Queues
最后,为了验证上面轮询调度、消息持久化和公平分发的特性,你可以多开几个 Shell 窗口,发几条长耗时的消息,然后停掉某一些worker 或重启 RabbitMQ 就能观察到与之相符的现象。